
程序分析通常有两种方法,分别基于数理逻辑和自然语言理解。通过将程序表示成图结构,来自微软研究院和西门菲莎大学的研究者展示了一种结合二者的新方法,可以直接从源代码中学习,且更准确地查找已发布软件中的 bug。
过去五年,基于深度学习的方法给大量应用带来了变革,如需要理解图像、话语和自然语言的应用。对于计算机科学家而言,一个自然出现的问题是:计算机是否能够学会理解源代码。乍一看这个问题似乎很简单,因为编程语言的设计初衷就是被计算机理解。但是,很多软件 bug 的出现是因为我想让软件这么做,但是写出来却是另外一回事。也就是说,小的拼写错误可能导致严重后果。
看一下以下这个简单示例:
float getHeight { return this.width; }.
该示例中,人类或者理解「height」和「width」意思的系统可以很快发现问题所在。源代码具备两种功能。首先,它与计算机进行准确交流,以执行硬件指令。其次,它与其他程序员(或源代码作者)针对程序的运行情况进行交流。后者通过选择代号、代码布局和代码注释来实现。在发现两种交流渠道似乎可以分离后,一个自动发现软件 bug 的系统出现了。
之前的程序分析主要关注程序的正式、机器可理解语义或将程序看作(有点奇怪的)自然语言。前者的方法来自于数理逻辑,要求对每个需要处理的新案例进行大量的工程工作。而自然语言方法需要在纯句法任务上性能优越但尚无法学习程序语义的自然语言处理工具。
在 ICLR 2018 的一篇论文《Learning to Represent Programs with Graphs》中,来自微软研究院和西门菲莎大学的研究者展示了一种结合二者的新方法,并展示了如何查找已发布软件中的 bug。
程序图
为了学习源代码中的大量结构,研究者首先把源代码转换成程序图( program graph)。图中的节点包括程序的 token(即变量、运算子、方法名等)及其抽象句法树的节点(定义语言句法的语法元素,如 IfStatement)。程序图包含两种不同类型的边:句法边,表示代码解析方式,如 while loop 和 if block;语义边,即简单程序分析的结果。
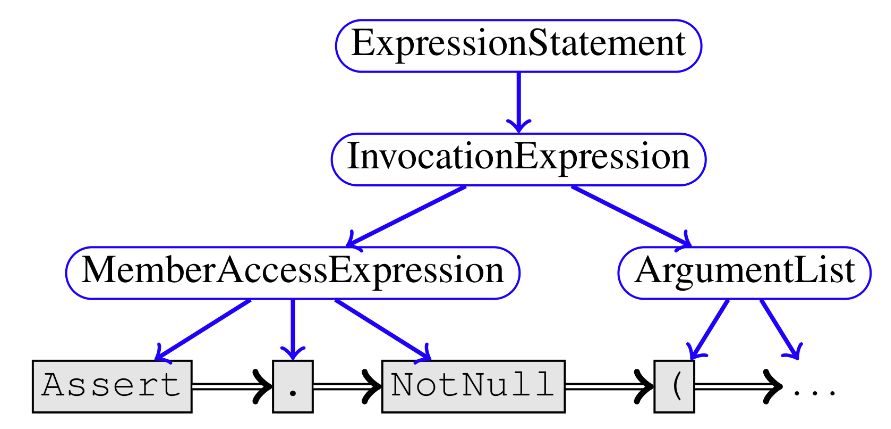
图 1:句法边
句法边包括简单的「NextToken」边、用于表示抽象句法树的「Child」边,以及连接一个 token 和源代码中它最后一次出现的「LastLexicalUse」边。图 1 展示了此类边用于 statement Assert.NotNull(clazz) 的部分示例,其中对应 token 的节点是灰色框,对应程序语法的非终端的节点是蓝色椭圆形框。Child 边是蓝色的实线边,而 NextToken 边是黑色的双线边。
语义边包括连接一个变量和它在程序执行中最后一次使用的「LastUse」边(如果是循环案例,则变量在程序执行中最后一次使用的情况出现得更晚一些)、连接一个变量和它最后一次写入的「LastWrite」边,以及连接一个变量和它据此计算的值的「ComputedFrom」边。也可能有更多语义边,利用程序分析工具箱的其他工具,如 aliasing、points-to 分析,以及程序条件。图 2 是在一个小代码段(黑色)上形成的一些语义边。
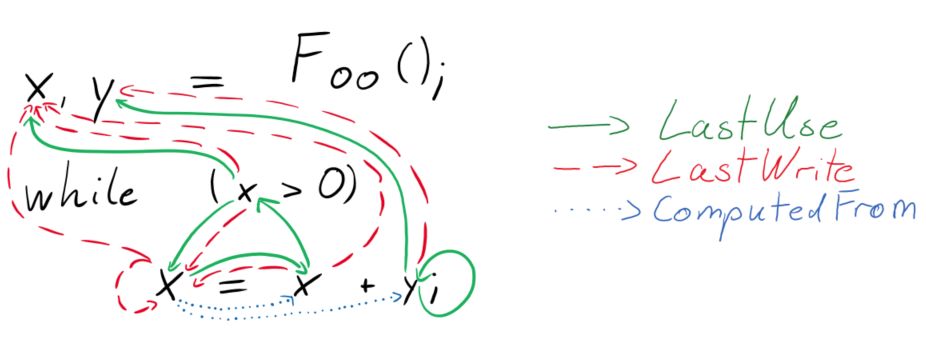
图 2:语义边
LastUse 关系用绿色边表示,y 与循环前 y 最后一次使用的情况连接。类似地,LastWrite 关系用红色边表示,while 条件中的 x 的使用与循环前 x 的分配和循环中 x 的分配连接起来。最后,ComputedFrom 关系用蓝色边表示,变量与其据此计算的变量连接起来。
句法边大概对应程序员在阅读源代码时所看到的。语义边对应程序如何执行。通过在一个图中结合二者,该系统可以比单一方法学习到更多的信息。
从图中学习
由于图通常作为表征数据和数据关系的标准方式,从图结构数据中学习的方法近期受到了一定程度的关注。一个组织可以用图的形式展现出来,正如药物分子可以看成是原子构成的图。近期成功的应用深度学习的图方法是图卷积网络(卷积神经网络的一种扩展)和门控图神经网络(循环神经网络的一种扩展)。
这两种方法都是首先独立地处理每个节点,以获取节点本身的内部表征(即低维空间中的一个向量),然后将互相连接的节点的表征进行重复连接(两种方法的组合方式不同)。因此,经过一个步骤之后,每个节点拥有自身的信息和它的直接近邻节点的信息;经过两个步骤之后,每个节点将获得距离两个节点的信息,以此类推。由于所有的步骤都使用(小型)神经网络,因此这些方法可以被训练用于从数据中提取整个任务相关的信息。
搜索 bug
在程序图上学习可以用于搜索 bug,例如本文开头描述的那个例子。给定一个程序、程序中的某个位置以及在该位置上可以使用的一系列变量。然后模型被询问应该使用哪些变量。为了执行这项任务,程序被变换为程序图,某个特定节点对应所考虑的位置。通过考虑该特定节点的计算表征,以及对应可用变量的节点表征,网络可以计算每个变量的可能性。这样的模型可以很容易地通过几百万行已有代码来训练,并且不需要专门标注的数据集。
当模型在新代码上运行,并以很高的概率预测出 var1,然而程序员选择的是 var2,这可能就是一个 bug。通过标记这些问题让人类专家审核,可以发现真正的 bug。例如,以下来自 Roslyn(微软 C# 编译器)的例子:
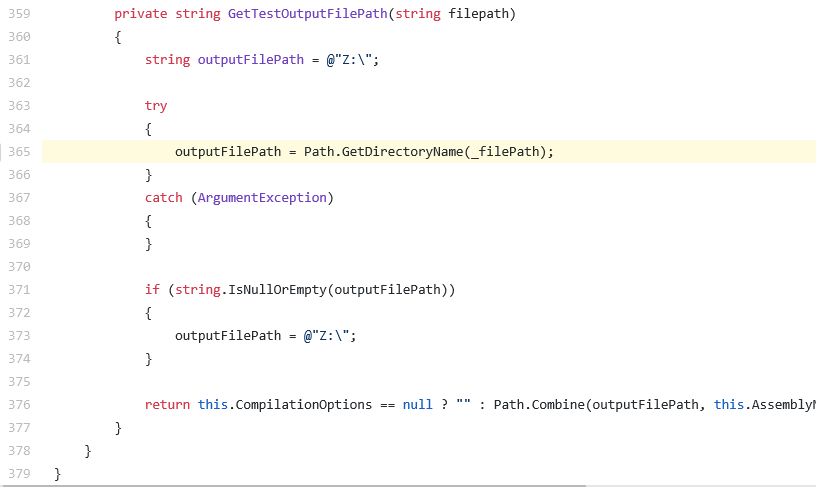
注意参数 filepath 和字段_filePath 的使用,二者很容易被混淆。然而,_filePath 只是一个打字错误,开发者在研究员报告这个问题和类似问题之后将其修改了。相似的 bug 在很多其它 C# 项目中也被找到、报告和修改。
在一个更大规模的定量评估中,新方法远远超越了传统的机器学习技术。作为基线方法,双向循环神经网络(BiRNN)直接在源代码上执行,BiRNN 的简单扩展可以访问数据流的某些信息。为了评估不同的模型,微软分析了包含 290 万行源代码的开源 C# 项目。在测试时,源代码的某个变量被遮盖,然后让模型找出原始使用的变量(假定源代码是准确并经过良好测试的)。在第一个实验中,模型在项目的留出文件上进行测试(其他文件用于训练)。在第二个实验中,模型在全新项目的数据上测试。结果如下表所示,在新的程序图上学习的模型得到了明显更好的结果。
未来应用
程序图对于在程序上应用深度学习方法是很通用的工具,微软将继续朝这个方向探索。

